三足鼎立:人工智能基础设施和服务市场寻索
 数据来源:《世界大战》
数据来源:《世界大战》
励石创投是一家专注于初创期风险投资和扩展期成长投资的风险投资机构,重点投资于运作主体在中国及美国市场的初创型及成长型企业。励石创投以“成为一家有价值、受尊敬、并具有国际影响力的投资机构”为愿景,结合其自身LP及产业链资源,通过对资本和管理的帮助,促进企业创新与成长。励石创投重点关注人工智能、企业服务、消费升级等领域的投资。
 数据来源:中信证券
数据来源:中信证券
概述:在万众瞩目的人工智能风起云涌之下,同步地涌动着一片基础设施和服务的蓝海市场机遇:大数据+软件架构+计算平台。但是这三大概念由来已久,又何以称得上是“蓝海”或“机遇”呢?励石创投认为,由于人工智能本身的革新性和特殊性,它的基础平台固然也带有革新性和特殊性。下面就让我们依次探索其中的洞天所在。
一、深度学习所需要数据不仅“大”,而且“深”
 数据来源:TechCrunch
数据来源:TechCrunch
正因为模型所需训练数据量和模型本身大小之间存在线性正相关联系,深度学习的主流模型——人工神经网络(ANN)——计算机有史以来最复杂的模型之一,才需要吸取大量的数据。但是,模型规模之所以大的一个关键目标是要充分捕捉到数据中不同部分的联系,例如图像的纹理与形状。模型所要解决的问题的复杂度越高,则其参数的个数越多,因此需要的训练数据本身就越复杂、精准、细节化。当今AI公司不惜余力所寻求的“标签数据”,正是经过一定程度预先处理的“大数据”。据供应商透漏,例如国内中科奥森和国外Identix类的人脸识别公司每年采购标签数据的预算高达百万元级别;自然语言处理(NLP)公司小i机器人备有多达数十人的训练数据预处理团队。预处理的目正是个性化地满足AI模型输出的函数参数和降维模式的特殊复杂度、精准度。

 数据来源:36氪
数据来源:36氪
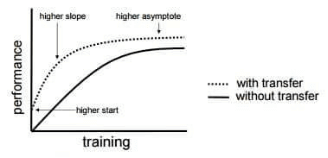
在国内,为AI行业提供定制化训练数据采集、预处理、交易、存储管理的公司已经涌现,并且有国外对标企业。顶图是美国MightyAI提供的数据标注产品Demo,该公司目前有50万外包者入住可随时接受数据采集和标注任务;底图则是两家国内的创业公司,不仅提供针对垂直领域细分的行业数据,而且可以针对模型训练的需求对特定场景进行定向采集。更重要的是,它们还对采集后的数据进行清理、标注及浅层预处理。两家公司在新三板上的市值均已接近甚至超过30亿人民币,年收入皆已超越数千万级别。励石创投认为,从目前VC基金所接触的该领域创业公司数量走势来看,比上述两家更专注于AI数据深度服务的公司即将随之而来。从训练技术本身的进展而言,数据“量”也呈现让步于“质”的趋势。例如在迁移深度学习(Transfer Learning)中,从类似数据源训练出的模型经个性化调整修改及补充完善,即可在命题领域得以重复使用。如下图所示,它能显著提高训练效率,用尽可能少量的数据训练出尽可能准确的模型。这里的前提只有一个:不同模型的输入数据类似命题的理想输入数据;并不强调数据应有多大的量。
 数据来源:TechCrunch
数据来源:TechCrunch
二、学无止境而算力有限——AI基架的魔法挑战
 数据来源:百度百家
数据来源:百度百家
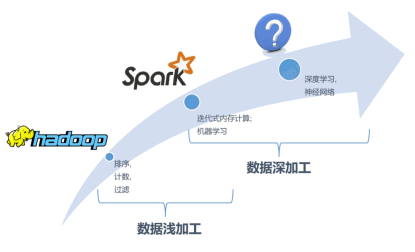
大数据刚刚兴起的时代,Hadoop能够利用CPU服务器帮助专家应用模型高效地完成清洗和规整等数据预处理任务。随之而来的云计算时代,Spark利用服务器集群分布式计算完成了机器学习等复杂模型与海量数据的衔接。现今深度学习步入主流的时代,软件架构必须与神经网络等数据深加工模型高效衔接,尽其所能发挥次世代多类芯片融合性能,实现低成本、低延迟的泛AI化计算愿景。此绝非易事:在计算资源受商业成本严格控制的情况下而迅速大数据刚刚兴起的时代,Hadoop能够利用CPU服务器帮助专家应用模型高效地完成清洗和规整等数据预处理任务。随之而来的云计算时代,Spark利用服务器集群分布式计算完成了机器学习等复杂模型与海量数据的衔接。现今深度学习步入主流的时代,软件架构必须与神经网络等数据深加工模型高效衔接,尽其所能发挥次世代多类芯片融合性能,实现低成本、低延迟的泛AI化计算愿景。此绝非易事:在计算资源受商业成本严格控制的情况下而迅速
 数据来源:高盛
数据来源:高盛
面对如此规模和刚性的市场需求,技术界各类群体纷纷推出自己的软件架构,以开源形式提供给行业开发者使用。当然,开源的原因并非此类服务不存在市场付费意愿。首先,作为人工智能行业的基础设施,此类软件如果在AI创业阶段借势大肆收费,只能取得拖延行业升腾步伐的双输后果。其次,该类软件的研发壁垒非同小可,使用者并不通晓其中原理和技巧,未来升级版本依托开源品牌效应的收费前景仍然看好。再次,由于AI底层硬件及顶层算法都处于非成熟阶段,中间软件本身也未达到成熟产品地步。国内外不乏投资开源团队的基金。目前最常用的开源架构包括下述7款,大多由科技巨头或顶尖院校研发:
谷歌——基于战果累累的DistBelief开源了更灵活的Tensorflow。DeepMind也转移到了它上面。它与Hadoop和Spark各有优劣,前者适合数据统计,后者适合数值计算。由于其通用性Tensorflow不算快。
伯克利大学——Caffe比Tensorflow更严格,专为CNN设计,按照功能的层层分类将神网分层,速度较快。Caffe含有实现数据在不同GPU上并行的指令,但不含实现神经网络在不同GPU上分布的指令。
DMLC组织——MXnet的通用性位于Caffe和Tensorflow之间。Tensorflow用全符号式,架构师要现设计好流程图再执行运算。流程图由层层张量和变量的函数组成。MXnet混合半功能式和半符号式,不仅适用于CNN,也用于RNN等。
亚马逊——DSSTNE可用稀疏数据解决问题,据说比TensorFlow快2倍。
微软——CNTK是目前最快的图像识别框架,搭配4颗Nvidia GPU可达4万FPS,相比Caffe2.4万,Tensorflow1.1万。它用学徒+师傅的学习模式,进步效率较高。
脸谱——Torch非常灵活,并拥有一个强大的社区。它可以实现各类神网。社区产生的驱动包括信号处理,并行处理,图像,视频,音频和语义等。Torch是经过GPU优化的。
蒙特利尔大学——Theano吐槽有坑的不少,且不支持多GPU。
OpenAI——Gym是增强学习的开发工具,带有对模型评分和分享的功能。它针对AlphaGo采用的热点技术而开源,想在此基础上建立一个模型测评的国际标准。
 数据来源:百度百家
数据来源:百度百家
需要强调的是,现阶段几乎所有AI类开源架构都存在各种各样的不足之处。Spark和Flink皆针对CPU集群设计,没有考虑新型硬件如GPU、FPGA和ASIC的可运算空间。Caffe、Theano和Torch的基因都针对单节点而生,难以支持分布式运算体系,缺乏扩展性。PaddlePaddle和Petuum均基于上一代分布式机器学习架构参数服务器而设计,无法有利支持变化多端的数据流处理模式,灵活性欠缺。即使较新的TensorFlow、MXNet和CNTK也基本沿用DryAd的构架思路,已能高效释放CPU集群特性,但在异构集群大趋势的面前却显得能效不足。随着AI硬件和算法迅速迭代升级,开发者越发顾虑起开源软件突显出的问题,不得不时常寻找最新款的架构或者花费功夫自己尝试调理优化,往往达不到期望的效果。
三、AI计算芯片最小、最Cool、最快的最终追求
 数据来源:PConline
数据来源:PConline
GPU的属性非常适合大规模并行运算,在深度学习领域发挥着巨大作用。GPU可以平行处理大量琐碎信息,深度学习所依赖的是神经网络系统,这一系统出现的原因正是在高速状态下多通道并列分析海量数据。与单纯使用CPU相比,GPU具有数以千计的运算单元,能够实现十至百倍的应用吞吐量。GPU已取代CPU成为部分数据科学家处理大数据的主流利器。
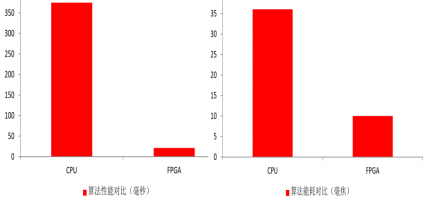 数据来源:百度百家
数据来源:百度百家
FPGA的运算速度和能量消耗比CPU优势明显。虽然它的频率一般比CPU低,但CPU是通用处理器来完成某个特定运算的,通常需要花费多个时钟周期。FPGA则能通过编程重组电路,从而直接生成专用电路,再加上电路并行的啊那排,或许只需一个时钟周期就能完成该运算。例如,CPU每次只能处理平均6个指令,而在FPGA上使用数据并行的方式每次能够处理256个以上的指令数目。
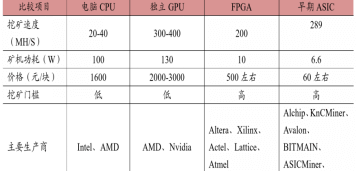 数据来源:巴比特
数据来源:巴比特
FPGA相对于GPU甚至也有明显能的耗优势。在FPGA中没有取指令与指令译码操作,而在GPU中取指令与译码消耗10%至20%的能耗。此外,FPGA 的主频比GPU低很多,通常 GPU在2GHz上下,而FPGA却在500MHz以下。频率差与功耗差成正比。基于FPGA平台的DPU更厉害,比现有FPGA产品提升20倍问题不大。真可谓山外有山!如上图所示,有望居于FPGA之上的后来者ASIC,算力和能效都直逼甚至超过了FPGA。
 数据来源:人加智能
数据来源:人加智能
励石创投认为,VPU作为DPU家族中的图像专属芯片,其潜力已被Intel近期巨额并购的Movidius所证实。励石已经投资的人加智能是中国首家走上此路的创业新星。上图为人加自主研发的测距优化策略及高能效FPGA芯片,为B端客户提供高性价比和实时运算性强的一体化方案。目前在高清分辨率下已能达到超低延迟效果,业内处于领先地位。其技术路线尤其专业级无人机领域具备十分显著的先天优势。从人加的先例可以看到,除了对最Cool和最快的追求,体积的小巧也是AI的一大需求。从VR头戴设备到机器人、从AR手机到无人机,随着各类智能终端性能指标的升级和能够采集到的数据量剧增,能本地化处理图像和语音识别等任务的芯片,是在对传输系统延迟敏感的场景中辅助乃至取代云计算的必备要素。
至今,该产业已悄然登场,并开始在一系列宽泛的智能终端及相关应用场景中开花:
 数据来源:Movidius
数据来源:Movidius
- 2016年2月——MIT实验室推出Eyriss,针对神经网络定的ASIC,通过减少数据移动、压缩、简化算法可达普通手机GPU十分之一即0.3W功耗,尤其如果对识别算法定制;
- 2016年2月——Movidius推出MA2450,将用于Google ProjectTango手机的位置和环境感知;
- 2016年3月——中计所推出寒武纪,神经网络算力比普通GPU高两个数量级,可用于手机进行刷脸支付、图片搜索、语音识别等应用;
- 2016年5月——Qualcomm推出Zeroth深度学习SDK,为最新Snapdragon定制,胜任一般图像和语音识别任务。Snapdragon820成本在200元上下;
- 2016年11月——Intel发布基于Nervana深度学习架构的KnightsCrest,类似Movidius的拍照视频识别USB芯片,可见其对在移动端的失利并不甘心;
- 2016年11月——创业公司ThinCI推出一种新CNN/DNN架构,利用极端平行串流数据、取代多个处理层连续处理,减少内存存取、提高分析性能,能效比普通GPU高13倍。公司即将基于此推出手机、AR、ADAS的FPGA。
 数据来源:乌镇互联网论坛
数据来源:乌镇互联网论坛
作为本文结语,励石创投选择投资的不仅是各类AI算法或其在关联领域的垂直应用,还有同是它们立身之本的技术平台,这样方可真正意义上地做到产业布局,为投后风险管控打下强有力的根基,也为资本运作创造十分有利的条件。而在此基础平台之中,励石关注的并非大数据、大规模运算架构、大规模运算平台,而是AI定制化数据、AI定制化运算架构、AI定制化运算平台,它们并非单一地追求“大”、“强”、“云”,而是高度策略化地努力满足人工智能应用算法现实场景需求的多重复杂维度。如此,方可真正意义上地为人工智能而做基础服务。
 数据来源:《励石创投AI产业布局》
关注励石创投!
数据来源:《励石创投AI产业布局》
关注励石创投!
